Session Information
Session Type: Poster Session C
Session Time: 9:00AM-11:00AM
Background/Purpose: The emergence of Large Language Models (LLM) with remarkable performance such as GPT-4 and ChatGPT, has led to an unprecedented uptake in the population. One of the most promising and studied applications for these models concerns education. Their ability to understand and generate human-like text creates a multitude of opportunities for enhancing educational practices and outcomes. The objectives of this study were to assess the success rate of GPT-4/ChatGPT in answering rheumatology questions from the access exam to specialized medical training in Spain (MIR), and to evaluate the medical reasoning followed by ChatGPT/GPT-4.
Methods: Rheumatology questions from the MIR exam published from 2010 onwards were selected and used as prompts. Questions present clinical cases or factual queries, followed by four to five responses with a single correct answer. Questions containing images were excluded.
Official responses were compared with those provided by GPT-4/ChatGPT to estimate the chatbots accuracy. Differences between LLM were evaluated using McNemar’s test.
A rheumatologist with teaching experience in preparing students for the MIR exam assessed the correctness of the medical reasoning of the LLM given for each of the questions, using a 5-point Likert scale, where 5 indicates that the reasoning was entirely correct. The influence in the medical reasoning score of the chatbot model used was analyzed using McNemar’s test. The influence of the year of the exam question, type of question (clinical case vs. factual), patient’s gender in the clinical case questions, and pathology addressed were assessed using logistic regression models, after dichotomizing the Likert scale into two groups: low score (i.e.,1,2,3) vs high score (i.e., 4, 5).
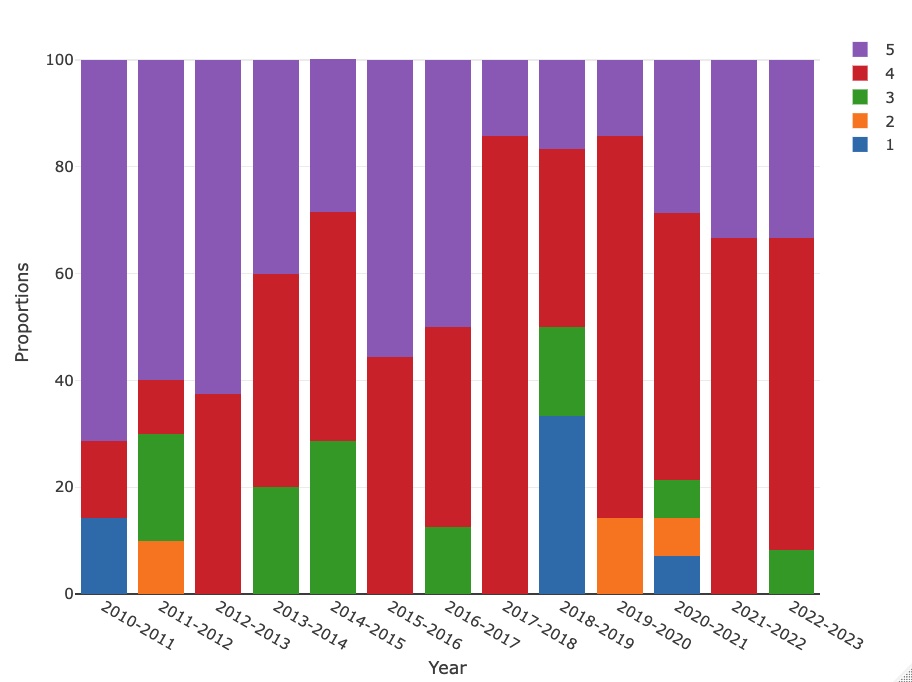
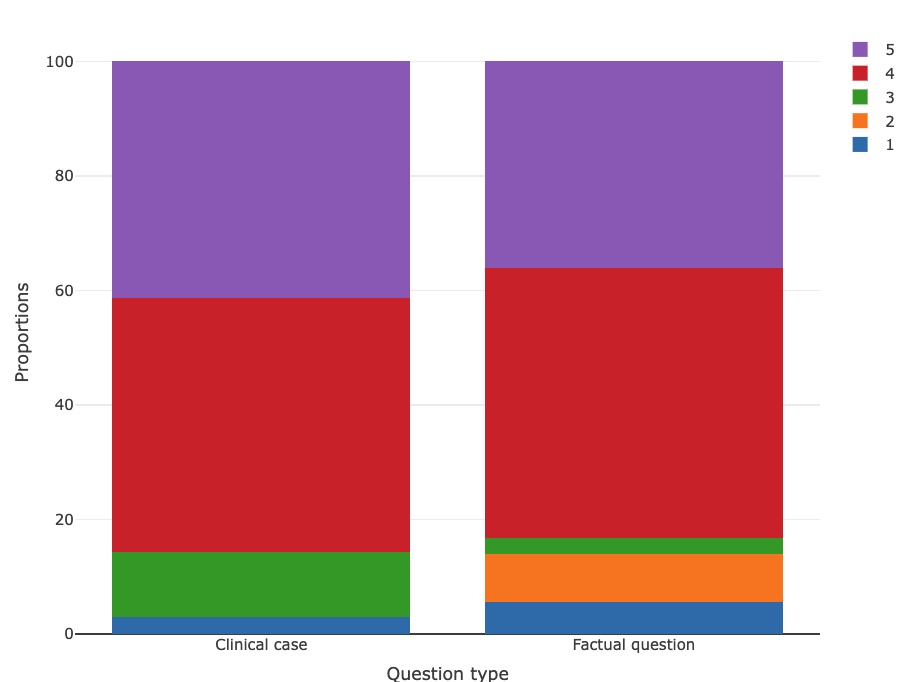
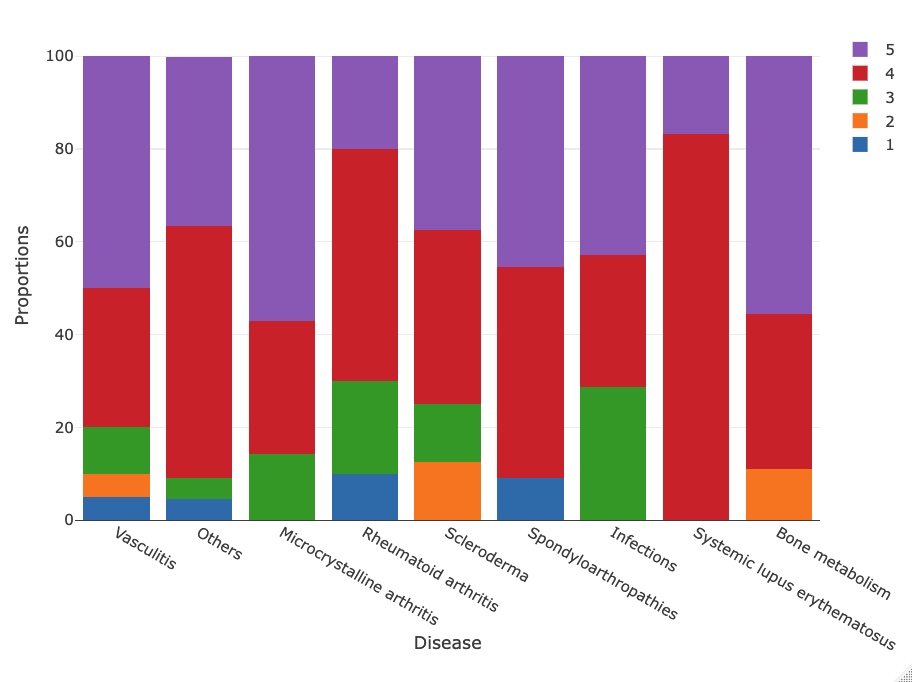
Results: After applying the inclusion criteria, 106 questions remained, including 36 (34%) factual queries and 70 (66%) clinical case questions. 99 (93.4%) and 69 (65.1%) questions were correctly answered by GPT-4 and ChatGPT, respectively. Most of the questions that GPT-4 failed were factual queries (5/7, 71.4%). We observed a significantly higher proportion of correct answers provided by GPT-4 (p=1.2×10-7). Moreover, the clinical reasoning score of this LLM was also higher (p=4.7×10-5). Regarding the other variables, there were no statistically significant differences in the clinical reasoning score for GPT-4/ChatGPT across the various categories studied. Figures 1, 2 and 3 show the scores given to each question, considering the year, question type and disease.
Conclusion: GPT-4 showed a significantly higher accuracy and clinical reasoning score than ChatGPT.
No significant differences in the clinical reasoning correctness were observed regarding the type of question or the condition evaluated.
GPT-4 could become a valuable asset in medical education, although its precise role still has to be defined.
To cite this abstract in AMA style:
Madrid García A, Rosales z, Freites D, Pérez Sancristóbal I, Fernandez B, Rodríguez Rodríguez L. Augmenting Medical Education: An Evaluation of GPT-4 and ChatGPT in Answering Rheumatology Questions from the Spanish Medical Licensing Examination [abstract]. Arthritis Rheumatol. 2023; 75 (suppl 9). https://acrabstracts.org/abstract/augmenting-medical-education-an-evaluation-of-gpt-4-and-chatgpt-in-answering-rheumatology-questions-from-the-spanish-medical-licensing-examination/. Accessed .« Back to ACR Convergence 2023
ACR Meeting Abstracts - https://acrabstracts.org/abstract/augmenting-medical-education-an-evaluation-of-gpt-4-and-chatgpt-in-answering-rheumatology-questions-from-the-spanish-medical-licensing-examination/