Session Information
Session Type: Poster Session B
Session Time: 10:30AM-12:30PM
Background/Purpose: The role of artificial intelligence (AI) is rapidly expanding in medical fields, with an increased frequency of use by both patients and providers. There is a paucity of data assessing the ability of AI chat models (also known as Large Language Models or LLMs) to accurately answer clinical questions and compare the accuracy of responses provided by different LLMs. This study aimed to investigate the ability of three LLMs (ChatGPT-4, Bard, and Bing) to respond accurately and with quality responses provided by different LLMs.
Methods: Rheumatology-related questions from the rheumatology section of the MKSAP-19 were entered into three LLMs (OpenAI’s ChatGPT-4, Microsoft’s Bing, and Google’s Bard) between April 26 to May 3, 2024. Questions were posted twice: once with the inclusion of multiple-choice answers to choose from and once without (posed as “answer this question”). The inclusion of laboratory values, imaging findings, and pathology findings within the question stem was noted. Generated responses were assessed based on overall accuracy and the number of correct answers, marked as correct, incorrect, or unable to answer. Statistical analysis was performed to determine the number of correct responses per LLM per category. Subgroup analysis was conducted based on question type. Data were reported as a proportion of correct answers per LLM and per question category in percentages (%); the threshold for significance was set at p=< 0.05.
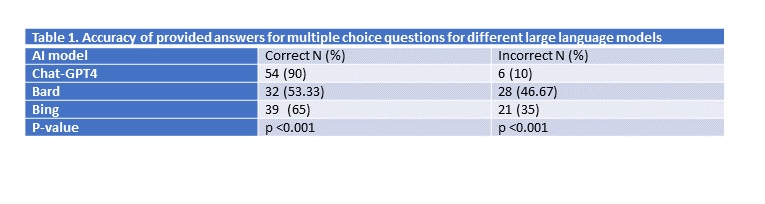
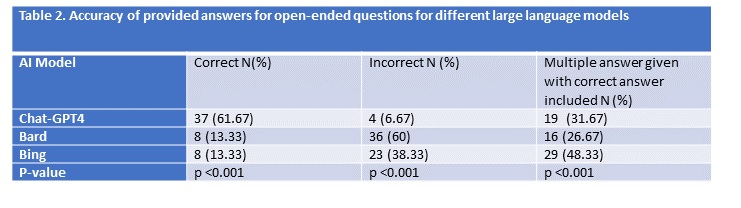
Results: A total of 60 questions were used to query the AI models, including 21 items of diagnosis questions, 3 items of epidemiology/risk factors questions, 11 items of investigations questions, 16 items of management questions, and 9 items of integrating diagnosis and management questions. The percentage of questions requiring laboratory interpretation was 53.33%, and 15% of questions included imaging findings. When questions were posed alongside multiple-choice answers, ChatGPT-4’s accuracy was 54 (90%), Bing’s accuracy was 39 (65%), and Bard’s accuracy was 32 (53.33%) (p < 0.001). When prompts were input into the LLMs in an open-ended fashion, ChatGPT-4 correctly answered 56 (93.34%), Bing correctly answered 37 (61.67%), and Bard correctly answered 24 (40%) (p < 0.001). ChatGPT-4 and Bing attempted to answer 100% of the questions, whereas Bard was unable to answer multiple-choice and open-ended questions, 21.67% and 38.33%, respectively. All three LLMs provided a rationale in addition to an answer, as well as counseling where appropriate.
Conclusion: LLMs demonstrate a promising ability to answer clinical questions in rheumatology, especially with ChatGPT-4. However, LLMs are dynamic entities whose accuracy will change over time requiring validation, and some LLMs showed limitations in accuracy and should be used with caution by healthcare providers, medical trainees, and patients.
To cite this abstract in AMA style:
Yingchoncharoen P, Chaisrimaneepan N, Pangkanon w, Thongpiya J. A Comparative Analysis of ChatGPT-4, Microsoft’s Bing and Google’s Bard at Answering Rheumatology Clinical Questions [abstract]. Arthritis Rheumatol. 2024; 76 (suppl 9). https://acrabstracts.org/abstract/a-comparative-analysis-of-chatgpt-4-microsofts-bing-and-googles-bard-at-answering-rheumatology-clinical-questions/. Accessed .« Back to ACR Convergence 2024
ACR Meeting Abstracts - https://acrabstracts.org/abstract/a-comparative-analysis-of-chatgpt-4-microsofts-bing-and-googles-bard-at-answering-rheumatology-clinical-questions/