Session Information
Session Type: Poster Session C
Session Time: 10:30AM-12:30PM
Background/Purpose: Despite Generative Pretrained Transformer Chat (Chat-GPT) is an artificial intelligence tool with the potential to assist doctors in diagnosing and treating patients, little is known about its assertiveness in the face of practical issues regarding autoimmune rheumatic diseases (ARDs). Therefore, we present a comparison between the answers provided by Chat-GPT 4.0 and rheumatologists of different degrees of experience to a specific questionnaire on Systemic lupus erythematosus (SLE), Rheumatoid arthritis (RA), Ankylosing spondylitis (AS),Psoriatic arthritis (PsA) and fibromyalgia (FM).
Methods: In this cross-sectional study we applied a questionnaire with five identical questions for each disease (SLE, RA, AS, PsA and FM, totaling 25 questions) to chat-GPT 4.0 and four pairs of rheumatologists with different levels of experience (less than 5 years of experience, 5 to 10, 11 to 20 and 21 to 30 years) being chosen 2 rheumatologists in each experience level. Two rheumatologists from academic services and with more than 30 years of experience blindly evaluated the responses in a binary way (agree or disagree). In case of discrepancy, a third rheumatologist from an academic service defined the evaluation.
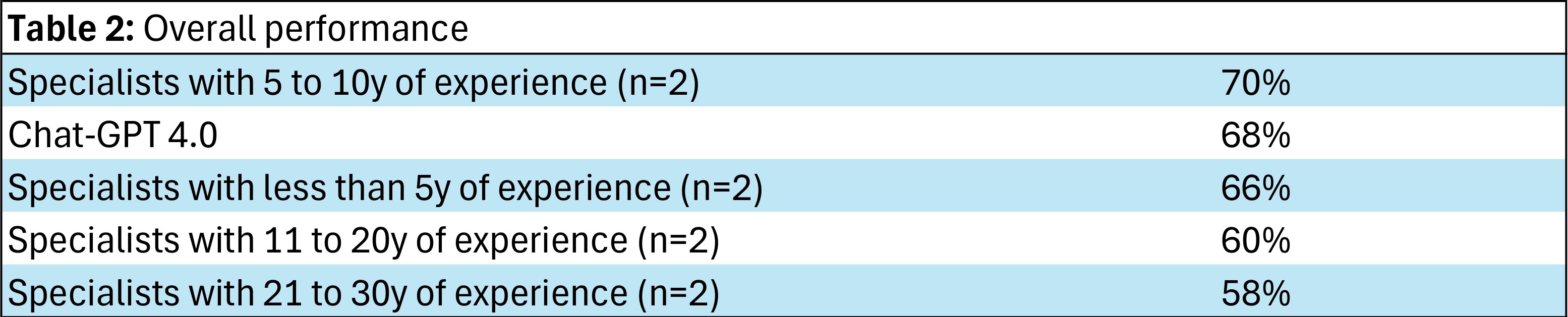
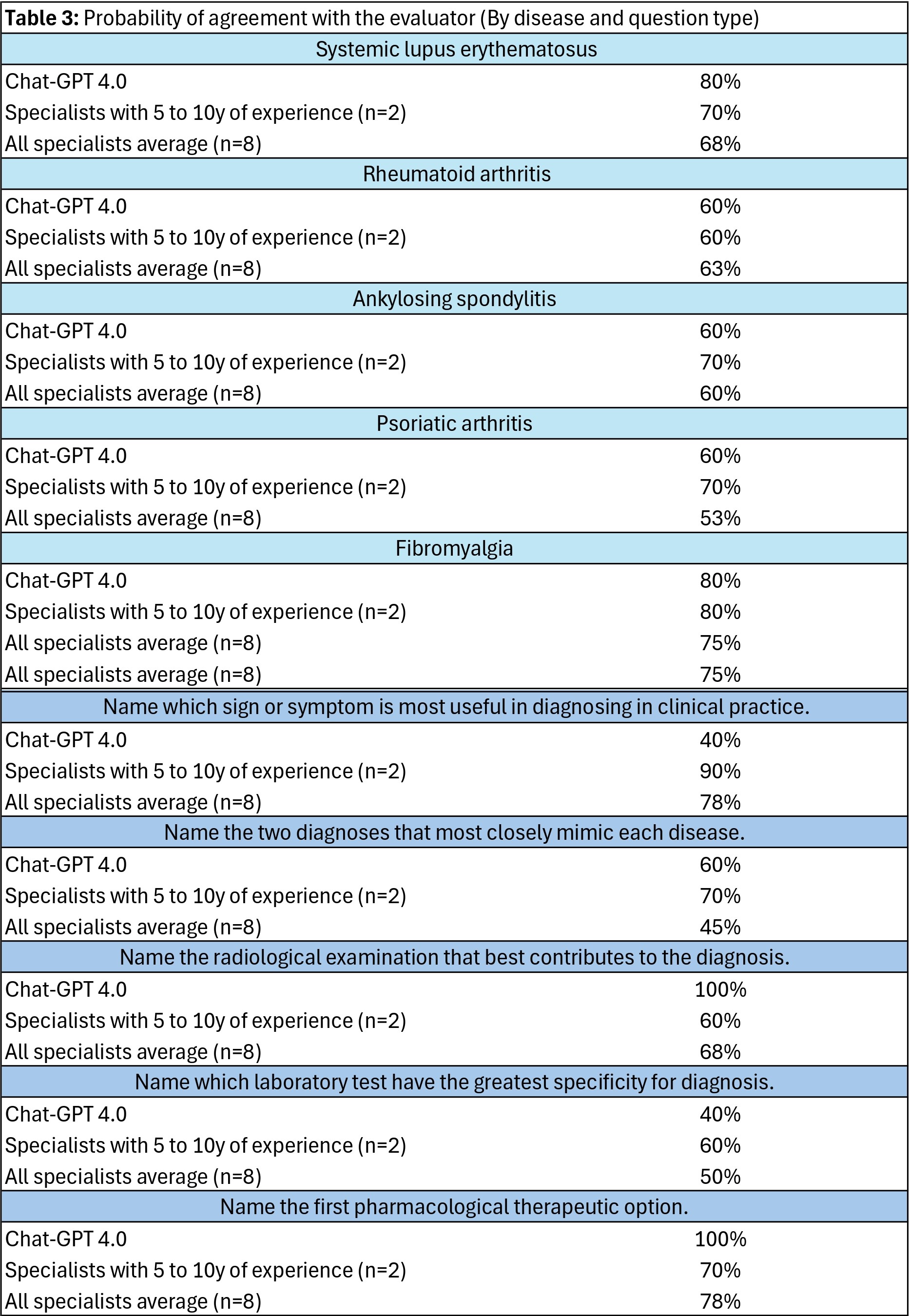
Results: The best overall performance was observed in the group with 5 to 10 years of experience (70% of agreement probability with the evaluators) followed by chat-GPT 4.0 (68%). The worst overall performance was from the group with 21 to 30 years of experience (58%). Chat-GPT outperformed all other groups in questions concerning the first option for treatment and the most effective imaging exams for investigation (100% in both). IA was the one with the worst performance in questions about chose the most useful sign or symptom for diagnose each disease (40% compared to 90% attained by rheumatologists with 5 to 10 years of experience). Chat-GPT performed best compared to all groups on questions about SLE (80%, tied with the group with less than 5 years of experience) and FM (80%, tied with the groups with 5 to 10 and 11 to 20 years of experience).
Conclusion: Chat-GPT 4.0 had an excellent performance in issues that require less practical knowledge (choice of treatment and imaging exam for diagnosis). On the other hand, it performed significantly poorly on questions about choosing the most useful sign or symptom for diagnosis, which are answers that require an experience-based knowledge. However, chat-GPT 4.0 performed very satisfactorily, achieving higher scores than many experts who participated in the study. Such results, more than confirming the superiority or invalidity of the machine, point to the need to carry out more robust studies that explore the potential of using AI in rheumatology.

*All questions were submitted in Brazilian Portuguese.
To cite this abstract in AMA style:
Goncalves L, Moura C. Chat-GPT Performance in Diagnosis of Rheumatological Diseases: A Comparison with Specialist’s Opinion [abstract]. Arthritis Rheumatol. 2024; 76 (suppl 9). https://acrabstracts.org/abstract/chat-gpt-performance-in-diagnosis-of-rheumatological-diseases-a-comparison-with-specialists-opinion/. Accessed .« Back to ACR Convergence 2024
ACR Meeting Abstracts - https://acrabstracts.org/abstract/chat-gpt-performance-in-diagnosis-of-rheumatological-diseases-a-comparison-with-specialists-opinion/