Session Information
Date: Monday, October 27, 2025
Title: (1248–1271) Patient Outcomes, Preferences, & Attitudes Poster II
Session Type: Poster Session B
Session Time: 10:30AM-12:30PM
Background/Purpose: Identifying informational needs of individuals with inflammatory arthritis is critical to enhancing communication and supporting shared decision making between patients, caregivers, and providers. However, qualitative methods require significant human effort, time, and specialized software. Our goal was to determine how effectively a large language model (LLM) could classify thematic categorization with human-labeled data from 2 nominal group technique (NGT) studies of individuals with inflammatory arthritis.
Methods: We utilized results from 2 separate NGT studies on the informational needs of individuals with inflammatory arthritis. The first identified information patients want prior to medication changes for juvenile idiopathic arthritis (JIA), including 2 virtual parent groups, 1 virtual adolescent group, and 1 asynchronous adolescent group. The second explored information priorities for adults living with inflammatory arthritis, collected over 6 virtual groups. Qualitative responses to the discussion questions were collected and ranked by participants. Responses were manually assigned themes by at least 2 members of the research team (gold standard). Six LLMs, including advanced proprietary models and open-source alternatives, were zero-shot prompted to assign a single best-fit theme from the human-generated codebook to each participant-generated statement. Model-assigned themes were compared to those assigned independently by 2 human coders. A match was defined as exact agreement between the model’s theme and the human-coded themes. Performance was evaluated using accuracy, macro F1 score, Cohen’s kappa, and Krippendorff alpha relative to each coder.
Results: The adolescent groups had 12 human-labeled and 12 LLM-assigned primary themes; the parent groups had 10 human-labeled and 11 LLM-assigned themes; the adult groups had 8 of each (Table 1). Model accuracy of theme assignment ranged from 65–82% for adolescent statements, 54–95% for parent statements, and 70–100% for adult statements (Table 2). Model agreement with human coders, measured by Cohen’s kappa, ranged from 0.70–0.80 for adolescent statements, 0.47–0.94 for parent statements, and 0.64–1.00 for adult statements. Human interrater Cohen’s kappa was 0.57 for adolescents, 0.59 for parents, and 0.74 for adults (Table 2).
Conclusion: LLMs can reliably approximate human coding of qualitative themes in NGT data, and in some cases showed stronger agreement with individual coders than the coders had with each other. Human- and model-assigned themes were often similar, with strong agreement across datasets. Models performed best when statements expressed clear, explicit themes but faced challenges with ambiguity or overlapping concepts. Performance was strongest for advanced reasoning models but remained robust across open-source and earlier-generation models. These findings support LLMs as scalable tools for thematic analysis in qualitative research. Future directions include refining prompts to assess statement salience and exploring LLM-guided theme discovery without predefined codebooks for flexible, data-driven identification of emerging concepts.
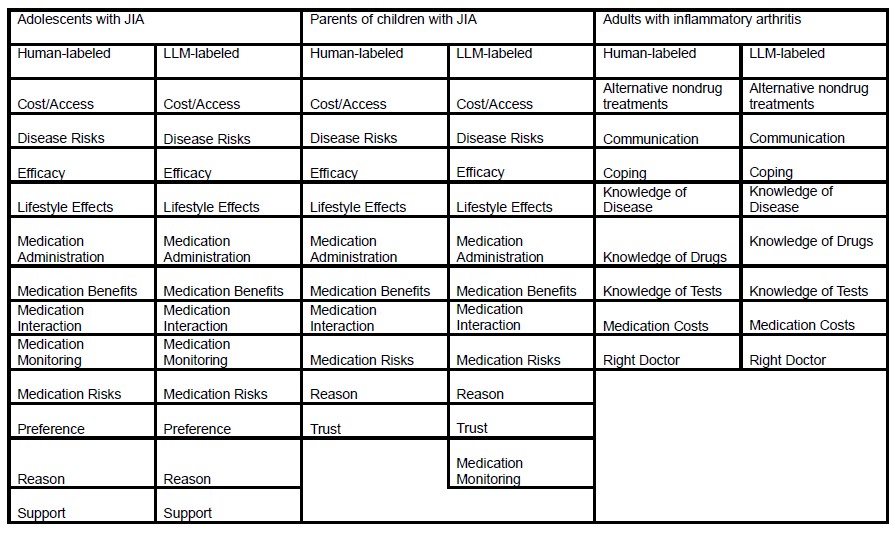 Table 1: Human and large language model (LLM) – assigned themes by participant group in 2 nominal group studies of patient informational needs
Table 1: Human and large language model (LLM) – assigned themes by participant group in 2 nominal group studies of patient informational needs
.jpg) Table 2: LLM-Human Interrater Reliability Metrics in Thematic Coding of NGT Responses
Table 2: LLM-Human Interrater Reliability Metrics in Thematic Coding of NGT Responses
.jpg) Figure 1: Workflow for Theme Assignment and Agreement Evaluation Between Human Coders and LLMs.
Figure 1: Workflow for Theme Assignment and Agreement Evaluation Between Human Coders and LLMs.
To cite this abstract in AMA style:
Mannion M, Thornton B, Mehta B, O'Beirne R, Smitherman E, Timmerman L, Venkatachalam S, Curtis J, Osborne J. Can LLMs Categorize Patient Priorities Like Humans? Comparing AI and Human Coders in Arthritis Nominal Group Discussions [abstract]. Arthritis Rheumatol. 2025; 77 (suppl 9). https://acrabstracts.org/abstract/can-llms-categorize-patient-priorities-like-humans-comparing-ai-and-human-coders-in-arthritis-nominal-group-discussions/. Accessed .« Back to ACR Convergence 2025
ACR Meeting Abstracts - https://acrabstracts.org/abstract/can-llms-categorize-patient-priorities-like-humans-comparing-ai-and-human-coders-in-arthritis-nominal-group-discussions/