Session Information
Session Type: Poster Session A
Session Time: 10:30AM-12:30PM
Background/Purpose: Unstructured data in physician notes can be incredibly valuable, especially for understanding patient-reported outcomes (PROs), which are often mentioned in these notes.In this study, we explore an Artificial Intelligence technique to efficiently extract patient-reported pain in Osteoarthritis (OA) patients by prompt engineering Large Language Models (LLMs). Prompt engineering is the process of designing inputs in LLMs to help to get insights from unstructured data. Our objective is to apply prompt engineering techniques to extract/predict patient-reported pain in physician notes in OA patients.
Methods: We used notes from patients with osteoarthritis at Internal Medicine screening (IM) and Orthopedic visits(ortho) enrolled in a registry before Total Knee Arthroplasty. A trained abstractor extracted pain scores (0-10) where they were explicitly stated. For notes without explicit scores, a board-certified IM physician estimated it based on the content. Notes were processed using the Llama 3.2-90B model, with a prompt engineered to extract 0-10 pain scores. (Figure 1). Prompt engineering techniques, such as Chain of Thought and Few Shot examples, were employed. Outside of the visits, patients reported a 0–10 pain score (Table 1). We calculated Kendall’s Tau-b to measure ordinal correlation between the LLM predictions, abstractor scores when present and patient reported pain. Physician predictions were analyzed for notes without scores.
Results: There were 159 patients in this study with corresponding ortho and IM notes. We identified 133 IM notes and 66 ortho notes that explicitly stated pain scores (Figure 2). In comparisons between pain scores extracted via a trained abstractor and the LLM, we observed a strong correlation in IM notes (τ = 0.81) and an even stronger correlation in ortho notes (τ = 0.99). In IM notes, 18 had a pain score written as 0 because the question was unanswered by patients, causing the EMR system to default to zero. In most cases, the LLM recognized and flagged these abnormalities. We then excluded the default zero and had a perfect correlation (τ = 1).For notes lacking explicit pain scores, the LLM predicted scores for 26 IM notes and 93 ortho notes. When comparing LLM-predicted pain scores to patient-reported pain scores obtained outside of the visit, the correlations were weak (IM: τ = 0.17, p = 0.30) (Ortho: τ = 0.09, p = 0.30). When a board-certified physician was asked to predict the scores, the correlation remained weak (IM: τ = 0.12, p = 0.46) (Ortho: τ = 0.13, p = 0.12).
Conclusion: When patient pain is explicitly documented in the chart, large language models (LLMs) can accurately extract this information, offering a potential time-saving tool for abstracting data from clinical notes. In contrast, when pain scores are not explicitly documented, LLM predictions are less accurate but still comparable to the performance of physicians attempting to infer scores from the same unstructured text. LLMs represent an efficient method for extracting information from clinical notes which may have variability in documentation when relevant data exist in unstructured form, opening new pathways for leveraging this information in both clinical care and research.
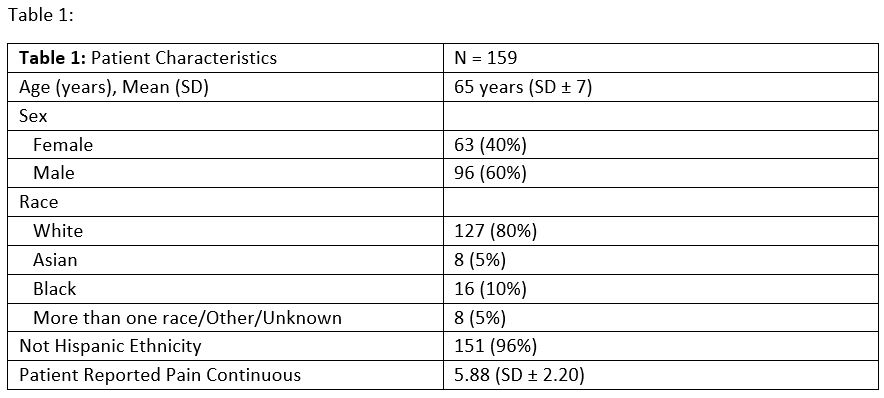 Table 1
Table 1
.jpg) Figure 1
Figure 1
.jpg) Figure 2
Figure 2
To cite this abstract in AMA style:
Doshi J, Batter S, Wu Y, Santilli A, Kannayiram S, Goodman S, Mehta B. Artificial Intelligence Assisted Extraction of Patient-Reported Pain Outcomes in Osteoarthritis Using Prompt Engineering of Large Language Models [abstract]. Arthritis Rheumatol. 2025; 77 (suppl 9). https://acrabstracts.org/abstract/artificial-intelligence-assisted-extraction-of-patient-reported-pain-outcomes-in-osteoarthritis-using-prompt-engineering-of-large-language-models/. Accessed .« Back to ACR Convergence 2025
ACR Meeting Abstracts - https://acrabstracts.org/abstract/artificial-intelligence-assisted-extraction-of-patient-reported-pain-outcomes-in-osteoarthritis-using-prompt-engineering-of-large-language-models/