Session Information
Session Type: Poster Session C
Session Time: 10:30AM-12:30PM
Background/Purpose: Artificial intelligence (AI) has shown promise as a tool to assist in clinical decision-making. Given the complex nature of autoimmune pathologies and the critical need for guideline-based precision in management, the relative efficiency of AI tools in answering specific rheumatology questions remains undetermined. This study aimed to evaluate the performance of three leading AI language models: ChatGPT (OpenAI), Bing AI (Microsoft), and Google Bard in responding to clinical questions in rheumatology, focusing on key domains of accuracy, relevance, response quality, and timeliness.
Methods: Physician reviewers structured a panel of 50 clinical questions with a rheumatology focus. Each question was submitted independently in plain text to Google Bard, Bing AI, and ChatGPT. Responses were anonymized and rated on a 5-point Likert scale for quality (clarity, completeness, and educational value), accuracy (clinical correctness and factual precision), and relevance (appropriateness and applicability to the question asked) by blinded Internal Medicine Residents to avoid bias. Response latency (in seconds) was recorded for each model via stopwatch timing from prompt submission to completion of response. Descriptive statistics were calculated, and one-way ANOVA was performed to detect significant differences across the models. Principal Component Analysis (PCA) was used for multivariate clustering to explore underlying patterns and potential clustering of model responses. All statistical analyses were conducted using R (v4.3.2). A p-value < 0.05 was considered statistically significant.
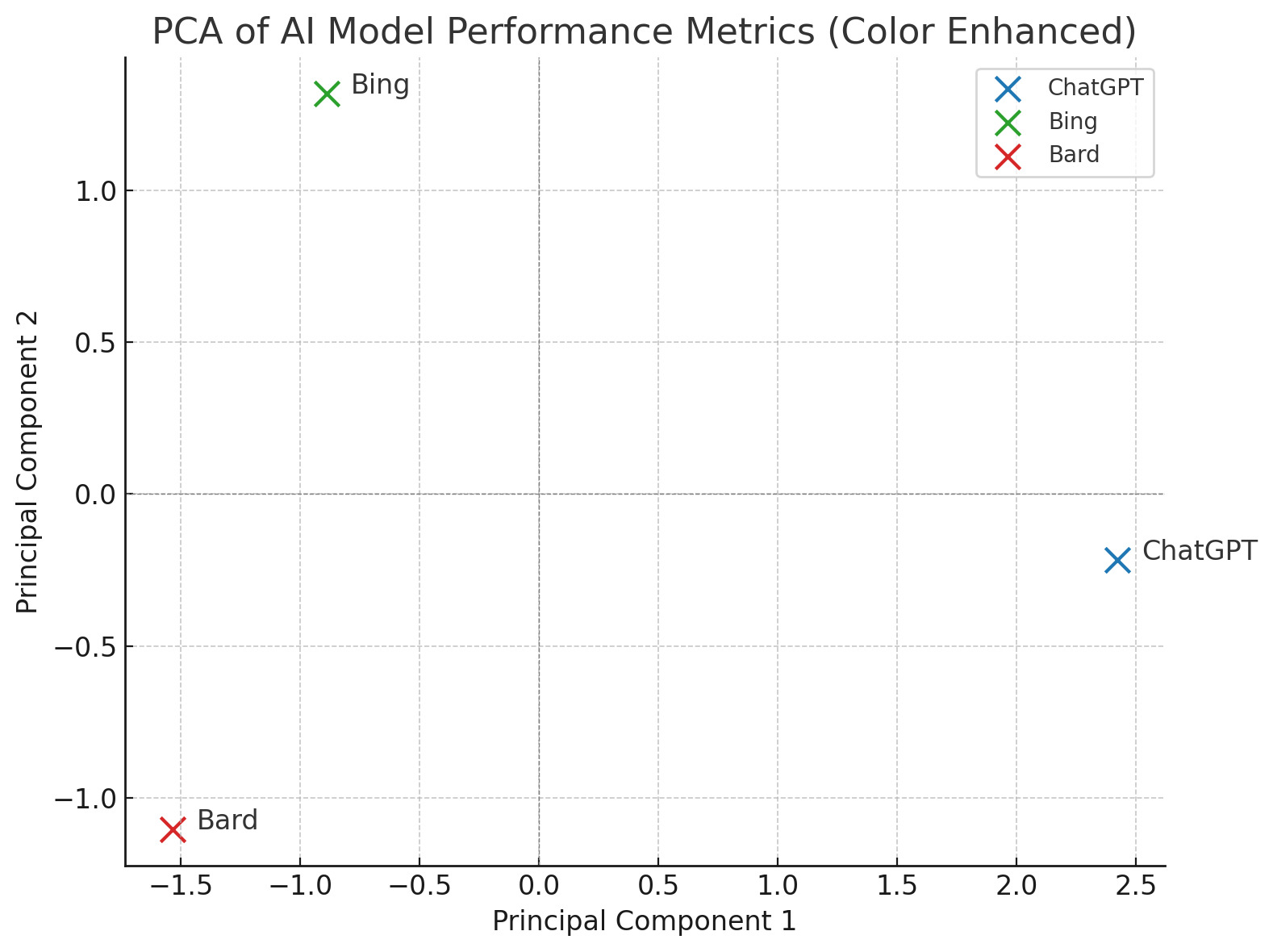
Results: ChatGPT scored highest in accuracy (mean ± SD: 4.36 ± 0.36) and relevance (4.64 ± 0.17), with statistically significant differences compared to Bing and Bard (ANOVA p < 0.001 for both). While ChatGPT also led in response quality (4.10 ± 1.10), the difference was not statistically significant(p = 0.064)*. Timeliness varied significantly among models, with ChatGPT responding fastest (19.4 ± 5.19s), followed by Bing (23.5 ± 5.54s) and Bard (28.0 ± 6.50s). PCA demonstrated that ChatGPT exhibited unique multidimensional performance by clustering independently.
Conclusion: Among the three AI systems evaluated, ChatGPT performed most proficiently in answering clinical rheumatology questions, with considerable improvements in accuracy, relevance, and timeliness. According to our research, generative AI models may be used as a supplement to clinical judgment in rheumatology, particularly in instances when quick and accurate synthesis of complicated data is essential.
 Comparison of AI Model Performance on Clinical Rheumatology Questions Using Likert Scale Metrics.
Comparison of AI Model Performance on Clinical Rheumatology Questions Using Likert Scale Metrics.
.jpg) Principal Component Analysis visualization of the AI models based on their multidimensional performance across accuracy, relevance, response quality, and timeliness.
Principal Component Analysis visualization of the AI models based on their multidimensional performance across accuracy, relevance, response quality, and timeliness.
.jpg) Likert scale metrics are scored on a 1–5 scale.
Likert scale metrics are scored on a 1–5 scale.
To cite this abstract in AMA style:
Pitliya A, Anam H, Oletsky R, Boc A, Chaudhuri D, Thirumaran R. Performance Comparison of Artificial Intelligence tools ChatGPT, Bing AI, and Google Bard for Clinical Rheumatology Decision Support: When AI Talks Rheumatology [abstract]. Arthritis Rheumatol. 2025; 77 (suppl 9). https://acrabstracts.org/abstract/performance-comparison-of-artificial-intelligence-tools-chatgpt-bing-ai-and-google-bard-for-clinical-rheumatology-decision-support-when-ai-talks-rheumatology/. Accessed .« Back to ACR Convergence 2025
ACR Meeting Abstracts - https://acrabstracts.org/abstract/performance-comparison-of-artificial-intelligence-tools-chatgpt-bing-ai-and-google-bard-for-clinical-rheumatology-decision-support-when-ai-talks-rheumatology/