Session Information
Session Type: Poster Session B
Session Time: 9:00AM-10:30AM
Background/Purpose: Patients with SLE can exhibit considerable clinical heterogeneity. A robust patient stratification approach can help to characterize individual lupus patients more effectively based on their molecular profile. Machine learning (ML) and analysis of molecular profiles can help to classify lupus patients more precisely, but proper validation is required for clinical implementation of these methods by rheumatologists.
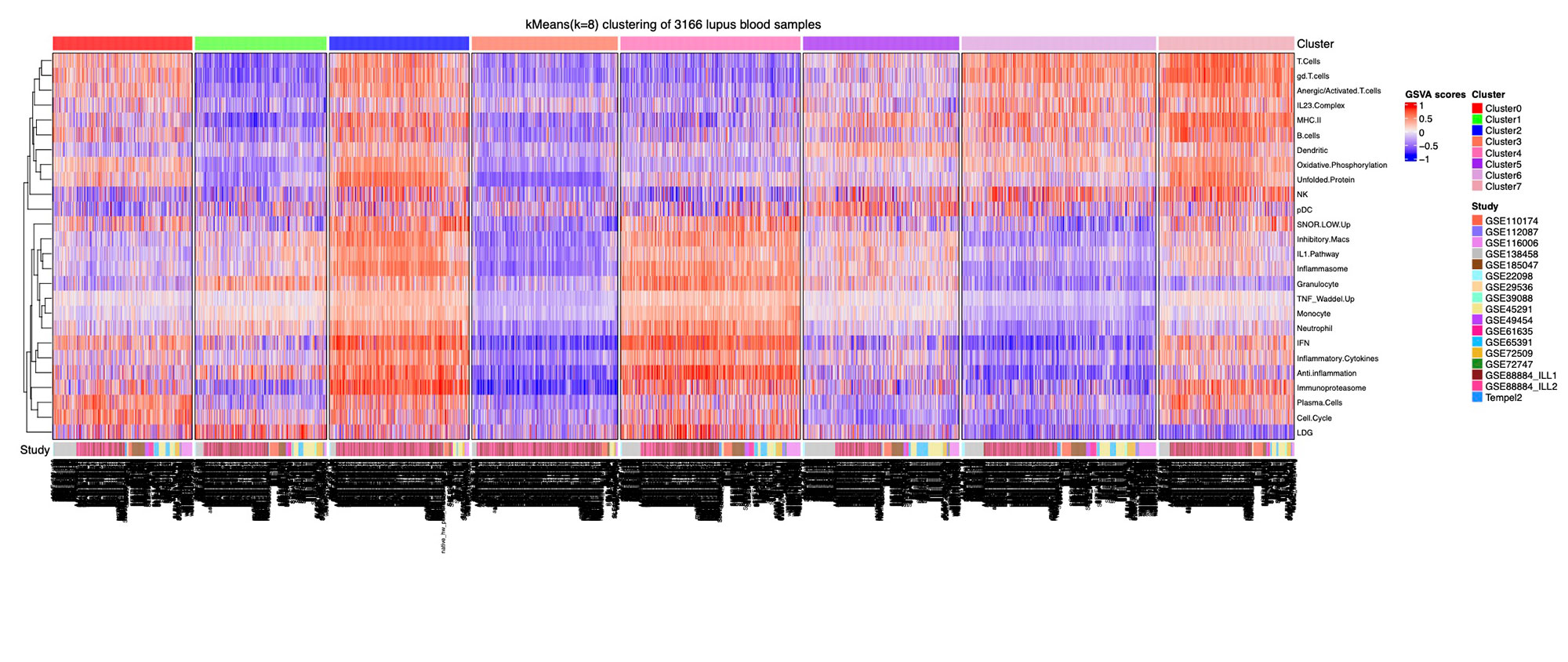
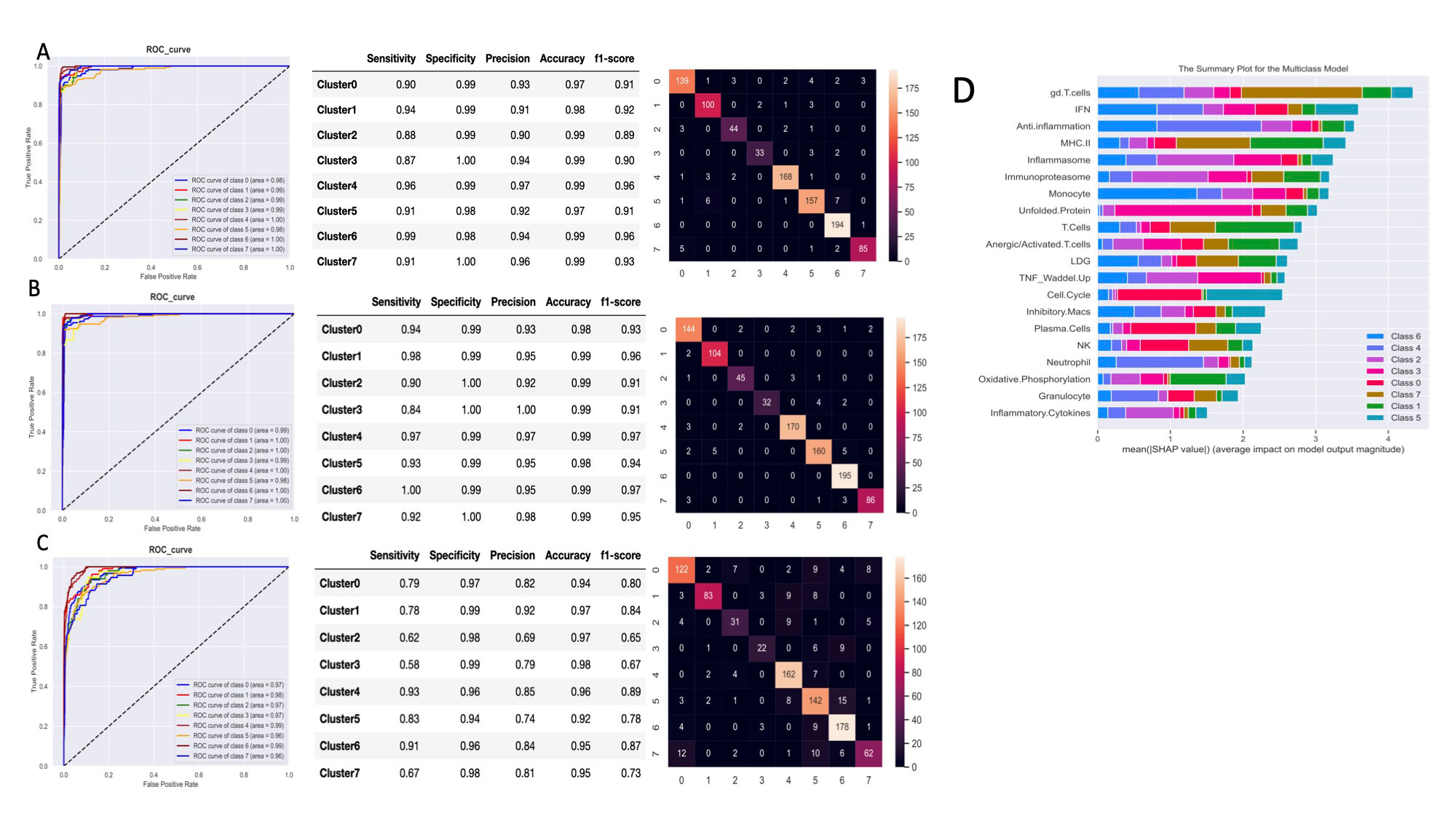
Methods: This study comprised 3,166 lupus samples extracted from 17 lupus blood gene expression datasets. Gene set variation analysis (GSVA) was carried out on each normalized dataset using 32 cell and process gene modules and resulting module enrichment scores were used as input into stable k-means clustering to subset lupus patients based on their gene expression profiles. We employed five different classification models including logistic regression (LR), Support Vector Machine (SVM), random forest (RF), and neural network to classify the lupus patients into patient subsets determined by k-means. The OnevsOne multi-class classification approach was used to avoid class imbalance. SHapley Additive exPlanations (SHAP) values were calculated for each patient subset to determine the most important features used in model prediction. The abnormalities of each lupus subset were summarized by a composite score developed by ridge regression modeling.
Results: Implementation of stable k-means clustering with the elbow method on GSVA scores of 3,166 lupus profiles identified eight subsets of lupus patients (Fig. 1). To evaluate and validate the classifiers, the trained models were applied to unseen data from 13 independent datasets. Among the four classifiers, SVM and LR performed best, with high degrees of accuracy (98%), precision (94%), sensitivity, and specificity (Fig. 2A-C). SHAP identified the IFN, monocyte, and anti-inflammation modules as the top contributors for classification of the lupus subsets (Fig. 2D). A composite molecular score, which comprised aggregate molecular scores of each GSVA gene module, was developed by ridge regression modeling and allowed for calculation of a molecular score for each lupus patient (Fig. 3A). A subset of patients was identified whose molecular scores were not different than those found in normal subjects, whereas other subsets of lupus patients had progressively higher scores indicative of the aggregation of molecular abnormalities. The composite molecular scores were significantly correlated with both anti-DNA titers and SLEDAI (Fig. 3B-C)
Conclusion: Altogether, the separation of lupus patients into molecular subsets was reproducible across 17 datasets. ML and SHAP allowed for the identification of key features necessary for the classification of distinct subsets of lupus patients and ridge regression permitted reduction of gene expression profiles to a score to assess lupus-related immune activity that correlated with clinical features. The implementation of a molecular score may provide a means to categorize lupus patients numerically based on the nature of each individual’s underlying molecular abnormalities.

To cite this abstract in AMA style:
Bachali P, Hubbard E, Kingsmore Allison K, He Y, Grammer A, Lipsky P. Development of a Novel Gene Expression-based Molecular Score That Characterizes Individual Lupus Patients [abstract]. Arthritis Rheumatol. 2022; 74 (suppl 9). https://acrabstracts.org/abstract/development-of-a-novel-gene-expression-based-molecular-score-that-characterizes-individual-lupus-patients/. Accessed .« Back to ACR Convergence 2022
ACR Meeting Abstracts - https://acrabstracts.org/abstract/development-of-a-novel-gene-expression-based-molecular-score-that-characterizes-individual-lupus-patients/