Session Information
Date: Monday, November 8, 2021
Session Type: Poster Session C
Session Time: 8:30AM-10:30AM
Background/Purpose: Studies of giant cell arteritis (GCA) rely on classifying temporal artery biopsies (TABs), the gold-standard diagnostic test. However, these results exist as free text, rather than discrete classifications stored in databases or tables. Automated phenotyping using TAB reports in the electronic medical record (EMR) can streamline GCA studies.
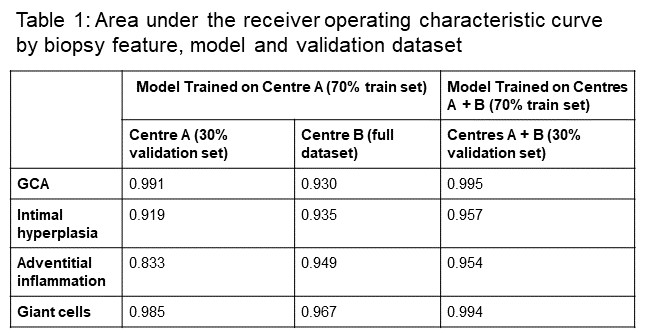
Methods: TAB reports from a single centre (Centre A) between January 2011 and November 2020 were manually classified according to the presence or absence of 4 features: intimal hyperplasia, adventitial inflammation, giant cells, and whether the TAB was diagnostic for GCA. The body of the biopsy reports was extracted using regular expressions, and the dataset was split into training (70%) and validation (30%) sets. All models were trained from a pre-trained DistilBERT (1) architecture, using the Transformers Python library (2) after text tokenization using a pre-trained tokenizer. This architecture is a light-weight neural network that uses multihead attention to learn word meaning from textual context (see figure 1). Summary statistics for Centre A are reported on the validation set, which was held out from model training. The models were then tested on an external cohort of TABs from another centre (Centre B), which were processed in an identical manner. Finally, the data from both centres was pooled, with the single centre method used to train and test a new model. Model performance was assessed with the area under the receiver operating characteristic (AUC).
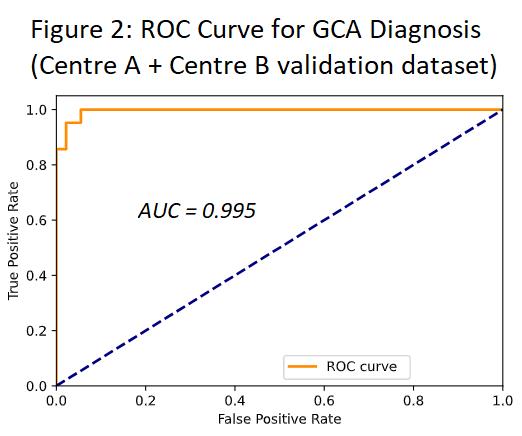
Results: 161 TAB reports from Centre A were included in the study, comprising 41 patients with GCA. The most uncommon histopathological feature was adventitial inflammation, occurring in just 23 of 161 patients (14%). Within the validation dataset, the model had excellent discrimination of GCA cases (AUC 0.991), and of most histopathological features (table 1). Testing the same model on Centre B (220 TAB reports, 35 cases of GCA), there was a drop in discrimination of GCA cases (AUC 0.930), although performance on adventitial inflammation improved. The model trained on the pooled dataset had improved performance on all four tasks, with almost perfect accuracy for discriminating GCA cases (see figure 2).
Conclusion: Machine learning algorithms can accurately classify TAB reports according to histopathological features. These algorithms are robust to changes in language between centres, but performance is improved with larger datasets. In practice, this could streamline studies of GCA by reducing the need for manual review of biopsy reports.
Sanh V, Debut L, Chaumond J, Wolf T. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter [Internet]. arXiv [cs.CL]. 2019. Available from: http://arxiv.org/abs/1910.01108
Wolf T, Debut L, Sanh V, Chaumond J, Delangue C, Moi A, et al. Transformers: State-of-the-Art Natural Language Processing. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Online: Association for Computational Linguistics; 2020. p. 38–45.

To cite this abstract in AMA style:
McMaster C, Yang V, Sutu B, Oon S, Ngian G, Wicks I, Buchanan R, Liew D. Temporal Artery Biopsy Reports Can Be Accurately Classified by Artificial Intelligence [abstract]. Arthritis Rheumatol. 2021; 73 (suppl 9). https://acrabstracts.org/abstract/temporal-artery-biopsy-reports-can-be-accurately-classified-by-artificial-intelligence/. Accessed .« Back to ACR Convergence 2021
ACR Meeting Abstracts - https://acrabstracts.org/abstract/temporal-artery-biopsy-reports-can-be-accurately-classified-by-artificial-intelligence/