Session Information
Date: Sunday, October 26, 2025
Session Type: Poster Session A
Session Time: 10:30AM-12:30PM
Background/Purpose: Low back pain (LBP) is a multifactorial condition managed by various specialists. AI chatbots like ChatGPT may help clinicians identify probable diagnoses. Given that query phrasing can influence outputs, we hypothesized that ChatGPT’s responses may vary depending on the specialty stated in the prompt.We aimed to evaluate whether ChatGPT’s diagnostic output changes when simulating different specialties in LBP assessment, and to compare its diagnostic accuracy to that of clinicians.
Methods: A total of 10 clinical cases related to LBP were included from official public exams for rheumatologists in Spain, designed to assess expertise for permanent specialist positions. These included 5 cases of rheumatologic diseases and 5 representing other causes. The exercise was conducted in December 2024 using ChatGPT version 4.o. Ten clinicians with at least 5 years of experience in managing rheumatic and musculoskeletal diseases (RMDs) participated in the study. Each question was answered independently by clinicians, and at a later stage by each participant asking ChatGPT, simulating five specialties (Rheumatology, Neurology, Internal Medicine, Rehabilitation, and Orthopedics). The gold standard was the official answer listed as diagnosis for each exam question. Diagnostic performance was evaluated using precision (percentage of cases where the top diagnosis matched the gold standard) and sensitivity (percentage of cases where the gold standard was included in the top three probable diagnoses). The time taken to answer all 10 clinical cases was recorded for both clinicians alone and using ChatGPT, starting when the case was reviewed and stopping when three differential diagnoses and the most probable diagnosis were finalized.
Results: In total, 528 free-text diagnoses were generated and standardized into 39 diagnostic categories. The percentage of the correct score for each participant and each prompted specialty is illustrated in Figure 1. Median precision ranged from 70% to 80% across the five specialties simulated by ChatGPT, and median sensitivity ranged from 80% to 90%. Statistical analysis revealed no significant differences in precision (p = 0.80) or sensitivity (p = 0.68) between the specialties simulated by ChatGPT, indicating consistent performance regardless of the prompted specialty. For clinicians, the median precision was 60%, and median sensitivity was 80%. When comparing ChatGPT to clinicians, ChatGPT had significantly higher diagnostic precision (median = 75% vs. 60%, p < 0.001) and significantly higher sensitivity (median = 85% vs. 80%, p = 0.02). The mean time taken by participants to complete the task was 12.35±5.62 minutes, compared to 2.33±0.03 minutes for ChatGPT (p< 0.01).
Conclusion: ChatGPT provides consistent diagnostic performance across simulated specialties, unaffected by the prompt’s semantic framing. It may outperform clinicians in both diagnostic precision and sensitivity, highlighting its potential as a valuable complementary tool for generating fast, accurate and comprehensive differential diagnoses in cases of low back pain. Further research is needed to explore its application in clinical practice and its ability to enhance diagnostic workflows.
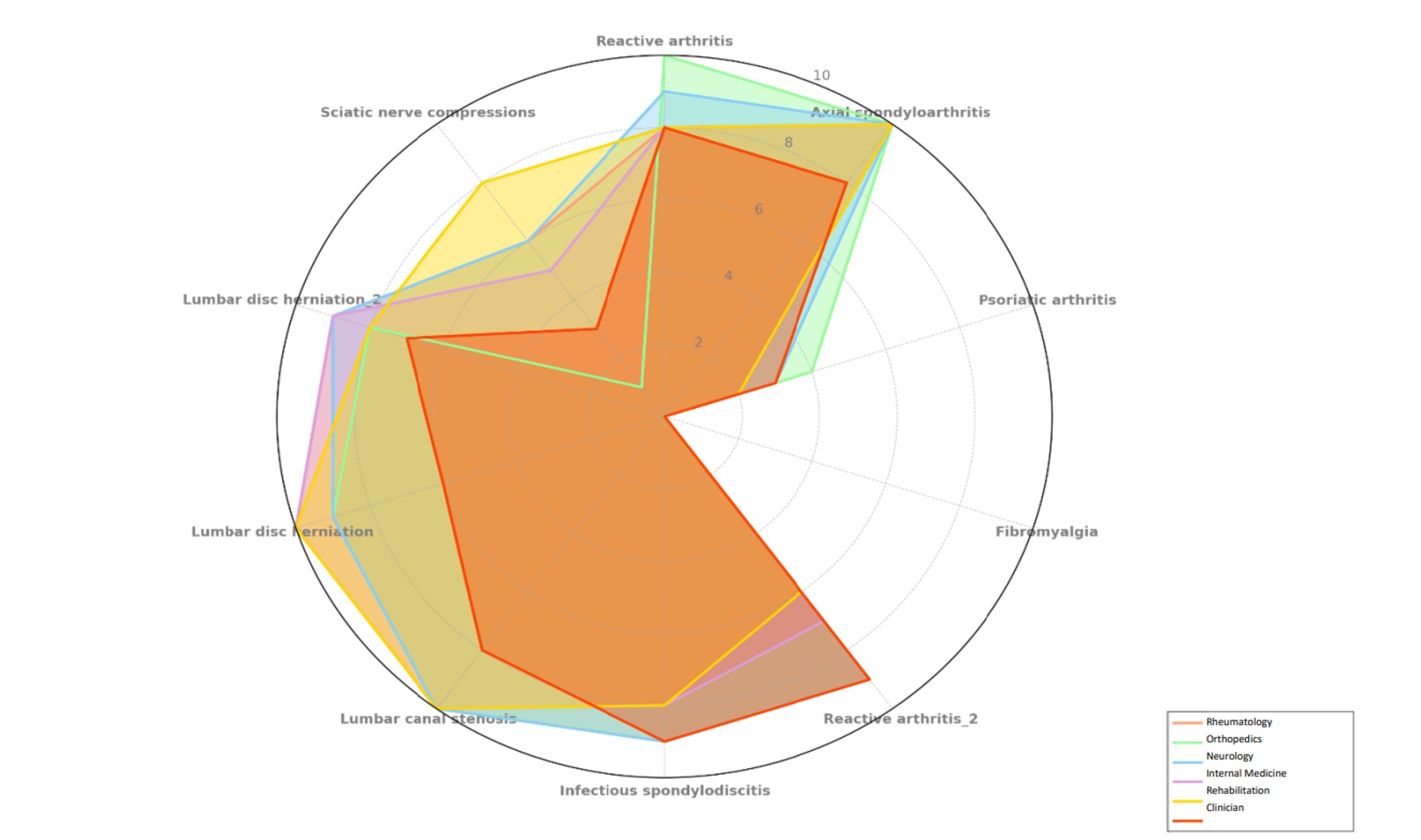 Figure 1. Percentage of the correct score for each participant and each prompted speciality
Figure 1. Percentage of the correct score for each participant and each prompted speciality
To cite this abstract in AMA style:
Nack A, Michelena Vegas X, Maymó-Paituvi P, Calomarde-Gómez C, lobo d, García-Alija A, Ugena-García R, Aparicio M, Vidal Montal P, Benavent D. Evaluating ChatGPT’s Performance in Diagnosing Low Back Pain: A Comparison with Clinicians and Impact of Prompted Specialties [abstract]. Arthritis Rheumatol. 2025; 77 (suppl 9). https://acrabstracts.org/abstract/evaluating-chatgpts-performance-in-diagnosing-low-back-pain-a-comparison-with-clinicians-and-impact-of-prompted-specialties/. Accessed .« Back to ACR Convergence 2025
ACR Meeting Abstracts - https://acrabstracts.org/abstract/evaluating-chatgpts-performance-in-diagnosing-low-back-pain-a-comparison-with-clinicians-and-impact-of-prompted-specialties/